Writings
Spring Data JPA Internals
2017-03-22
In the previous post[1], I showed how brief it can be for Spring Data JPA to expose routine CRUD interfaces of simple database entities. This post goes a little bit further, by revealing the work Spring has done behind the scenes, and why we can interact with the database with the methods we declared in interfaces without implementing them.
I’ll start with Spring AOP.
Spring AOP Proxy
AOP (Aspect Oriented Programming) is a very common programming paradigm, it encapsulates logics and action from an another angle comparing to OOP(Object Oriented Programming). OOP encapsulates data and actions into classes, mostly correspond to domain models; but in runtime, it’s data flows from one module to another, so it’s more like a lot of chains consisting of business logics we wrote, and this is where AOP takes over. Let’s say normal method calling chains are vertical, then AOP cuts in from the horizontal angle, which encapsulates common logics like logging, auth, and cache etc into aspects. And AOP also uses IoC[2] to make sure original code and logics remain intact while the extracted aspects take all responsibilities.
AOP is capable of doing something like this: “Print a warning log to console for every java methods processing POST requests in all controllers”. Like I said the extracted entity doing the job is called aspect, the predicate describing “every java methods processing POST requests of all controllers” is called pointcut, and the action “print a warning log to console” is called advice.
AspectJ is the founding predecessor of AOP in Java world, Spring AOP reuses some annotations, but implements on its own, and the core tech it uses is AOP Proxy. For example, we have an interface and one implementation called SimplePojo, calling SimplePojo’s foo() method looks like this:

And if we create a proxy for SimplePojo, it looks like this:
 (Both images come from Spring official documentation)
(Both images come from Spring official documentation)
That being said, the proxy proxies the original method calling, and we can execute our advice inside the proxy. The following code demonstrates how to create a proxy with Spring AOP’s lower-level APIs.
public interface I {
}
public class C implements I {
public String m() { return "m in C"; }
}
public interface I2 extends I {
String m();
String m2();
}
void proxyDemo() {
ProxyFactory result = new ProxyFactory();
result.setTarget(new C());
result.setInterfaces(I2.class);
result.addAdvice(new MethodInterceptor() {
@Override
public Object invoke(MethodInvocation invocation) throws Throwable {
if (invocation.getMethod().getName().equals("m2")) {
return "m2 in proxy";
}
return invocation.getThis().getClass().getMethod(invocation.getMethod().getName()).invoke(invocation.getThis());
}
});
I2 proxy = (I2) result.getProxy();
System.out.println(proxy.m()); //Output: `m in C'
System.out.println(proxy.m2()); //Output: `m2 in proxy'
}
Here are explanations:
- I declared an interface
I - I defined a class
Cinheriting interfaceI, and within which I also defined a methodm - Interface
I2inherits interfaceI, and I declared 2 methods (mandm2) in it ProxyFactoryis Spring AOP’s factory class for proxy. I instantiated it, set its target to an object ofC, set proxied interface toI2, and added a method interceptorMethodInterceptoris an interface, the overridden methodinvokedoes the actual work, which in our case are: a) intercepts method call tom2, return Stringm2 in proxy, and b) redirects all other method call (justmin our case) to the target (aCobject in our case)
After a brief introduction to Spring AOP proxy, now I can partly answer the question I asked in the beginning: why we can call methods we declared in interfaces without implementations? Actually the demo above is a simplified version of Spring Data JPA implementation.
public interface ItemRepository extends CrudRepository<Item, String> {
List<Item> findByName(String name);
}
For Spring Data JPA, when we declare an interface like above, Spring firstly creates a bean named itemRepository, and it, of course, is a proxy, which is initialized and configured in RepositoryFactorySupport[3]. The target of this proxy is SimpleJpaRepository[4], it contains basic CRUD methods like save(), and delete() etc by using EntityManager. The proxied interfaces are ItemRepository and Repository[5]. There are multiple method interceptors in the proxy, the one deal with Query Method is this one, what it does is iterating all query methods in ItemRepository, creating a RepositoryQuery object for each of them and add to a map[7].
Once our code invoke itemRepository.findByName(), the thread immediately goes into invoke method of the method interceptor[8]. The interceptor judges if the method we are calling is query method[9] at first, if it is, fetch RepositoryQuery and execute with parameters, otherwise just call corresponding methods in SimpleJpaRepository[10].
Mini Parser
Now let’s move on to the 2nd part of the question: how does Spring find out our intention and complement implementation details only by the declared method name findByName?
It’s not magic at all if we take a deeper thought into it, since we need to comply to certain rules when composing query methods[11], the exact same rules which can be used by Spring to parse and generate JPA query objects. The entry point for parsing is here[12], and the object generated to interact with database is RepositoryQuery[7].
This mini parser is a hand-written, top-down parser, nothing fancy, no BNF expressions, no parser generators. The topmost node class is PartTree[13], which contains 2 child nodes subject and predict. subject represents query results you want, and predicate represents conditions just like what it means. For findByName, subject is empty and predicate is Name; and for more complicated one like findDistinctUserByNameOrderByAge, subject is DistinctUser while predicate is NameOrderByAge.
Subject class has 3 boolean fields: distinct, count, delete, and a integer field maxResults[14]. query is true if query method starts with findDistinct, count methods set count to true, the same for delete, and maxResults holds the value for limiting queries like findFirst10ByLastname.
Predicate has an ArrayList nodes which contains all OrPart nodes for query method name split by Or, as you can see this is how and-or-precedence implemented. And there is also an orderBySource node contains sorting nodes[15].
I am not going further, since it’s just trivial parser implementations. And this is the AST for a relatively long query method findDistinctByStateAndCountryLikeOrMapAllIgnoringCaseOrderByNameDesc:
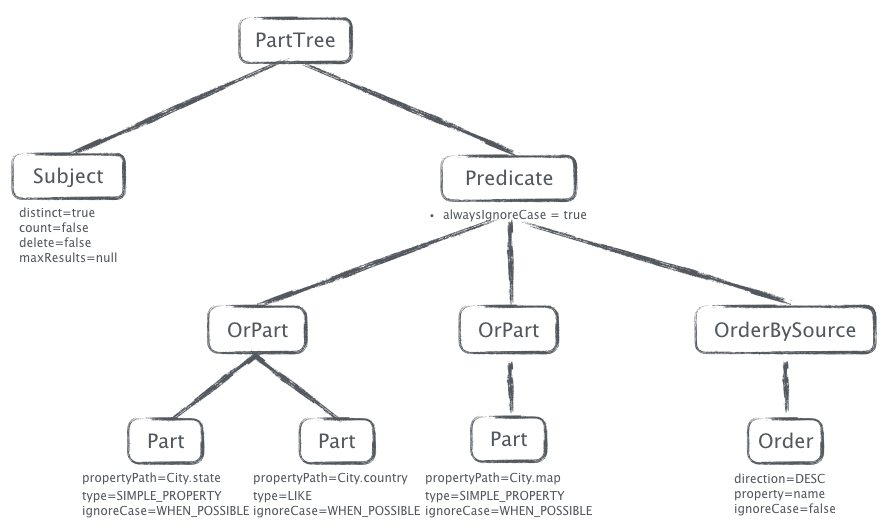
Once Spring has the AST, Spring Data will call JPA interfaces to create objects like Predicate and CriteriaQuery, then hand them over to JPA to query the database[16].
The rules and the parser are extremely simple and crude, ambiguities are very common, nonetheless, it’s totally acceptable since it’s just a helping tool. If ambiguous situations occur, just rename the field name, or, use named query[17] instead.
References
- [1]https://github.com/lxdcn/posts/blob/master/spring-introduction.md
- [2]https://en.wikipedia.org/wiki/Inversion_of_control
- [3]https://github.com/spring-projects/spring-data-commons/blob/01f2c30b1d1c342e168b3b541974332cc429e3e2/src/main/java/org/springframework/data/repository/core/support/RepositoryFactorySupport.java#L177
- [4]https://github.com/spring-projects/spring-data-jpa/blob/fda74889de51e586bfa22033aed0affb6f7f4c76/src/main/java/org/springframework/data/jpa/repository/support/SimpleJpaRepository.java
- [5]https://github.com/spring-projects/spring-data-commons/blob/01f2c30b1d1c342e168b3b541974332cc429e3e2/src/main/java/org/springframework/data/repository/core/support/RepositoryFactorySupport.java#L190
- [6]https://github.com/spring-projects/spring-data-commons/blob/01f2c30b1d1c342e168b3b541974332cc429e3e2/src/main/java/org/springframework/data/repository/core/support/RepositoryFactorySupport.java#L375
- [7]https://github.com/spring-projects/spring-data-commons/blob/01f2c30b1d1c342e168b3b541974332cc429e3e2/src/main/java/org/springframework/data/repository/core/support/RepositoryFactorySupport.java#L415
- [8]https://github.com/spring-projects/spring-data-commons/blob/01f2c30b1d1c342e168b3b541974332cc429e3e2/src/main/java/org/springframework/data/repository/core/support/RepositoryFactorySupport.java#L438
- [9]https://github.com/spring-projects/spring-data-commons/blob/01f2c30b1d1c342e168b3b541974332cc429e3e2/src/main/java/org/springframework/data/repository/core/support/RepositoryFactorySupport.java#L461
- [10](https://github.com/spring-projects/spring-data-commons/blob/01f2c30b1d1c342e168b3b541974332cc429e3e2/src/main/java/org/springframework/data/repository/core/support/RepositoryFactorySupport.java#L467
- [11]http://docs.spring.io/spring-data/jpa/docs/current/reference/html/#repositories.query-methods.query-creation
- [12]https://github.com/spring-projects/spring-data-jpa/blob/master/src/main/java/org/springframework/data/jpa/repository/query/JpaQueryLookupStrategy.java#L95
- [13]https://github.com/spring-projects/spring-data-commons/blob/01f2c30b1d1c342e168b3b541974332cc429e3e2/src/main/java/org/springframework/data/repository/query/parser/PartTree.java#L76
- [14]https://github.com/spring-projects/spring-data-commons/blob/01f2c30b1d1c342e168b3b541974332cc429e3e2/src/main/java/org/springframework/data/repository/query/parser/PartTree.java#L275
- [15]https://github.com/spring-projects/spring-data-commons/blob/01f2c30b1d1c342e168b3b541974332cc429e3e2/src/main/java/org/springframework/data/repository/query/parser/PartTree.java#L342
- [16](https://github.com/spring-projects/spring-data-commons/blob/01f2c30b1d1c342e168b3b541974332cc429e3e2/src/main/java/org/springframework/data/repository/query/parser/AbstractQueryCreator.java#L98
- [17]http://docs.spring.io/spring-data/jpa/docs/current/reference/html/#jpa.query-methods.named-queries